Curious trends in arXiv submission data
There was a curious discussion at Peter Woit's blog concerning recent arXiv submission trends. It was observed (after some initial confusion) that the number of revisions appeared to have increased dramatically in the last month or so.
An (AI generated) analysis, available on GitHub, confirmed this pattern. The data look like this.

What causes that surge in revisions (red) versus posts (blue)? This recent trend appears in all arXiv categories. The AI declares that it is a real trend and speculates that authors are submitting revisions using generative AI tools. I'm naturally skeptical, so thought someone should least build a statistical model of what this plot might look like, assuming nothing but a stationary process.
So I did. I took submissions per month to be about 250 $$ n \sim \textrm{Po}(250) $$ and assumed that authors posted a revision upon publication to match the published version, about six months later, $$ d \sim \textrm{Po}(6) $$ What do you know?
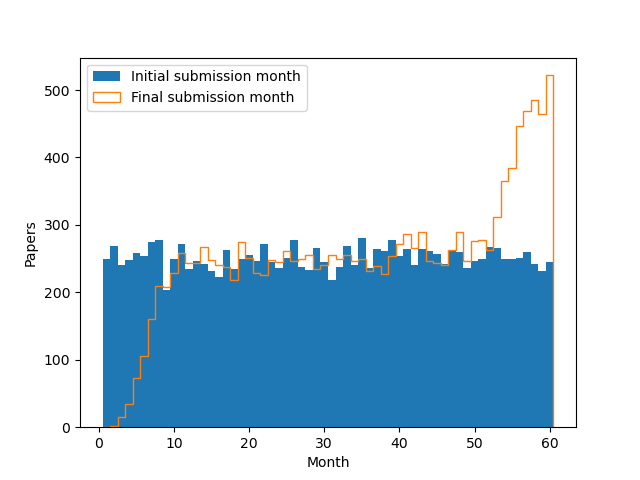
In the current month (here month 60), you see the first submissions (that haven't been replaced yet) and revisions (from papers from previous months). In past months, you only see revisions, as the first submissions are later replaced.
This was an interesting example of a stationary that process produces a mirage of non-stationary behaviour (a surge in the current month). The explanation about AI revisions is unwarranted. On the other hand, there is almost certainly non-stationary behavior in the dataset, as, e.g., the number of academics has increased over time.
Don't take my word for it, of course. Run it yourself. I'd love to see a Bayesian analysis that constructed a principled model and fitted it to the actual data.
"""
arXiv submission patterns
=========================
"""
import numpy as np
import matplotlib.pyplot as plt
rate_per_month = 250
publication_time_months = 6
end_month = 60 # 5 years
def simulate():
# make papers
initial = []
for i in range(end_month):
initial += np.random.poisson(rate_per_month) * [i + 1]
# now post a new version after publication some time later
published = [a + np.random.poisson(publication_time_months)
for a in initial]
# final update before end of simulation
final = [b if b <= end_month else a for a, b in zip(initial, published)]
return initial, final
if __name__ == "__main__":
initial, final = simulate()
bins = np.arange(0.5, end_month + 1, 1)
plt.hist(initial, bins=bins, label="Initial submission month")
plt.hist(final, bins=bins, histtype="step", label="Final submission month")
plt.legend()
plt.xlabel("Month")
plt.ylabel("Papers")
plt.savefig("arxiv.png")
Tags: code, ai, arxiv, statistics
mp3 player
I am trying to reduce my dependence on smartphones, as I have found them intrusive and distracting. I have a simple mp3 player that I can copy files to via USB-A. I like the design as I don't need a separate cable. It looks something like this one.

It does support bluetooth headphones, but bluetooth earpods are easy to lose and have to be charged, so I am sticking with wired headphones.
With that hardware, I need some sofware for subscribing to and downloading podcasts that I listen to. I used to do this using the iPhone podcast app. I like to use computers using the keyboard and command-line. I found existing libraries overly complicated. I want to run a script that updates the mp3 player and that's it.
Thus, I created my own solution. The podcasts I want to listen to are stored as good-old-fashioned RSS feeds in a JSON file:
{
"download_path": "~/podcasts",
"sync_paths": [
"/media/sdb1/Podcasts/"
],
"default_keep": 1,
"feeds": [
{
"url": "https://podcasts.files.bbci.co.uk/b0070hz6.rss"
},
{
"url": "https://podcasts.files.bbci.co.uk/p02nrsln.rss"
},
{
"url": "https://podcasts.files.bbci.co.uk/b006qpgr.rss"
},
{
"url": "https://podcasts.files.bbci.co.uk/p02nrsc7.rss"
},
{
"url": "https://podcasts.files.bbci.co.uk/p09k7ctp.rss"
},
{
"url": "https://podcasts.files.bbci.co.uk/p02nrsjn.rss"
},
{
"url": "https://librivox.org/rss/14834",
"keep": "all"
}
]
}
There are settings to control the number of episodes that are kept.
A Python script reads this configuration, downloads episodes using requests, discards old episodes, and syncs it with the device using rsync. Thus, I plug in the mp3 player, run the script, and wait.
"""
Podcast downloader
==================
"""
import os
import re
import json
import shutil
import subprocess
from pathlib import Path
import feedparser
import requests
from requests.adapters import HTTPAdapter
from urllib3.util.retry import Retry
RC_FILE = Path.home() / ".config" / "ypod.json"
session = requests.Session()
retries = Retry(total=5, backoff_factor=1, status_forcelist=[502, 503, 504])
adapter = HTTPAdapter(max_retries=retries)
session.mount("http://", adapter)
session.mount("https://", adapter)
MIME_TYPES = {
"audio/mpeg": ".mp3",
"audio/mp4": ".m4a",
"audio/aac": ".m4a",
"audio/x-m4a": ".m4a",
"audio/ogg": ".ogg",
"audio/opus": ".opus",
}
def safe_filename(text):
"""
Convert string into lowercase, underscore-separated, strictly alphanumeric filename
"""
text = text.lower()
# Replace any non-alphanumeric character with underscore
text = re.sub(r"[^a-z0-9]+", "_", text)
# Collapse multiple underscores
text = re.sub(r"_+", "_", text)
# Strip leading/trailing underscores
text = text.strip("_")
return text
class Config:
"""
Manage a config file
"""
def __init__(self, rc_file):
if not rc_file.exists():
raise FileNotFoundError(f"Config not found: {rc_file}")
self.rc_file = rc_file
with open(self.rc_file, "r") as f:
self.config = json.load(f)
@property
def download_path(self):
return Path(self.config["download_path"]).expanduser()
@property
def feeds(self):
return self.config["feeds"]
@property
def default_keep(self):
return self.config.get("default_keep", 1)
@property
def default_archive(self):
return self.config.get("default_archive", True)
@property
def sync_paths(self):
sync_paths = self.config.get("sync_paths", [])
return [Path(p).expanduser() for p in sync_paths]
def deduce_file_ext(entry, audio_url):
"""
Guess file extension ahead of time
"""
# Try URL
url_file_ext = os.path.splitext(audio_url)[1].split("?")[0]
if url_file_ext:
return url_file_ext
# Check RSS enclosure type
if "type" in entry.enclosures[0]:
mime = entry.enclosures[0].type
if mime in MIME_TYPES:
return MIME_TYPES[mime]
# Head request
try:
resp = session.head(audio_url, allow_redirects=True, timeout=10)
mime = resp.headers.get("Content-Type", "").split(";")[0]
if mime in MIME_TYPES:
return MIME_TYPES[mime]
except:
pass
# Fallback to mp3
return ".mp3"
def download_entry(index, entry, download_path):
"""
Download single entry from feed
"""
episode_title = safe_filename(entry.title)
if not entry.enclosures:
print(f"Skipping {episode_title}: no audio found")
return None
audio_url = entry.enclosures[0].href
file_ext = deduce_file_ext(entry, audio_url)
file_name = download_path / f"{index}_{episode_title}{file_ext}"
if file_name.exists():
print(f"{file_name.name} already downloaded")
return file_name
with session.get(audio_url, stream=True, timeout=30) as response:
response.raise_for_status()
total_size = int(response.headers.get("content-length", 0))
if total_size == 0:
total_size_display = "?"
else:
total_size_display = f"{total_size / (1024 * 1024):.1f} MB"
chunk_size = int(0.5 * 1024 * 1024)
downloaded = 0
with open(file_name, "wb") as f:
for chunk in response.iter_content(chunk_size=chunk_size):
if chunk:
f.write(chunk)
downloaded += len(chunk)
downloaded_display = f"{downloaded / (1024 * 1024):.1f} MB"
print(
f"\r{file_name.name} [{downloaded_display} / {total_size_display}]",
end="",
flush=True,
)
print() # move to next line after completion
return file_name
def process_feed(feed, config):
"""
Process a feed by downloading latest episode
and archiving old ones
"""
print(f"\nProcessing feed: {feed['url']}")
resp = session.get(feed["url"], timeout=5)
parsed = feedparser.parse(resp.content)
if not parsed.entries:
raise IOError(f"No episodes found in {feed['url']}")
feed_title = safe_filename(parsed.feed.get("title", "unknown_feed"))
print(f"Feed title: {feed_title}")
# Download files
latest_path = config.download_path / "latest" / feed_title
latest_path.mkdir(parents=True, exist_ok=True)
entries = sorted(
parsed.entries, key=lambda e: e.get("published_parsed", 0), reverse=False
)
indexed_entries = list(enumerate(entries))
keep = feed.get("keep", config.default_keep)
if keep == "all":
keep = len(entries)
latest_entries = indexed_entries[-keep:]
latest_file_names = [download_entry(i, e, latest_path) for i, e in latest_entries]
latest_file_names = [f for f in latest_file_names if f is not None]
# Move any old files from latest
archive = feed.get("archive", config.default_archive)
previous_path = config.download_path / "previous" / feed_title
for f in latest_path.iterdir():
if f not in latest_file_names:
if archive:
previous_path.mkdir(parents=True, exist_ok=True)
target = previous_path / f.name
shutil.move(str(f), str(target))
print(f"Archived: {f.name}")
else:
os.remove(str(f))
print(f"Deleted: {f.name}")
def sync(download_path, sync_path):
"""
Sync latest episodes with e.g. USB mp3 player
"""
if not sync_path.exists():
print(f"\nSkipping sync: {sync_path} not found")
return
print(f"\nSyncing: {sync_path}")
src_folder = download_path / "latest"
dst_folder = sync_path / "latest"
dst_folder.mkdir(parents=True, exist_ok=True)
cmd = [
"rsync",
"-av", # archive mode + verbose
"--delete", # delete files on destination that are missing locally
str(src_folder) + "/", # trailing slash important
str(dst_folder) + "/",
]
subprocess.run(cmd, check=True)
rc_dest = sync_path / "ypod.json"
shutil.copy(RC_FILE, rc_dest)
print(f"Copied RC file file to: {rc_dest}")
script = os.path.abspath(__file__)
script_dst = sync_path / os.path.basename(script)
shutil.copy(script, script_dst)
print(f"Copied current script to: {script_dst}")
def main():
print(f"ypod! Config at {RC_FILE}")
config = Config(RC_FILE)
config.download_path.mkdir(parents=True, exist_ok=True)
for feed in config.feeds:
try:
process_feed(feed, config)
except IOError as e:
print(f"Error processing {feed}: {e}")
for p in config.sync_paths:
sync(config.download_path, p)
if __name__ == "__main__":
main()
Tags: mp3, smartphone, podcasts, code